
SQL básico
Los más relevantes y básicos ejemplos del uso de SQL para la captura de datos tabulares. La forma esencial de obtener la información necesaria.
Simple
Partiendo simple
SELECT * FROM ordenes LIMIT 5;
-- cuenta de los distintos productos desde ventas SELECT count(distinct idproducto) FROM ventas; -- las ventas realizadas del producto id=89 SELECT idproducto, sum(cantidad) as total FROM ventas WHERE idproducto = 89;
-- titulo y el año de estreno de las películas emitidas en 1990 y 2000 y con una duración mayor a dos horas.
SELECT titulo, year
FROM peliculas
WHERE year IN (1990,2000)
AND duracion > 120
-- el titulo e idioma de las películas con idioma ingles, español o francés
SELECT titulo, idioma
FROM peliculas
WHERE idioma IN ('English', 'French', 'Spanish')
-- Obtenga todos los detalles de las películas en español estrenadas después del 2000, pero antes del 2010
SELECT * FROM peliculas
WHERE idioma = 'Spanish'
AND year > 2000
AND year < 2010
-- Obtener el porcentaje de personas que ya no están vivas. Alias el resultado como porcentaje_muerto. ¡Recuerda usar 100.0 y no 100! SELECT (count(muerte)*100.0)/count(*) AS porcentaje_muerto FROM persona -- numero de años entre la película mas vieja y la mas nueva. establezca el resultado como ‘diferencia’ SELECT max(year) - min(year) AS diferencia FROM peliculas
Agregaciones
-- el total de productos vendidos SELECT sum(cantidad) FROM ventas; -- la mayor cantidad de venta de un producto SELECT max(cantidad) FROM ventas; -- total de unidades vendidas por producto (los primeros 5 más vendidos) SELECT idproducto, sum(cantidad) as total FROM ventas GROUP BY idproducto HAVING cantidad > 0 ORDER BY total DESC LIMIT 5; -- cuantas consultas por usuario medico (simple) SELECT count(idmedico), ex_idm as medicos FROM consultas c GROUP BY idmedico -- lista de edades y cantidad de pacientes para cada edad SELECT DISTINCT count(*),pa_edad FROM bio_pacientes bp GROUP BY pa_edad ORDER BY pa_edad
Categorías con Case
-- define un serie de categorías en base al precio. Crea una nueva columna 'nivel' con la categoría evaluada.
SELECT id, articulo, precio,
CASE precio WHEN < 500 THEN 'BAJO'
WHEN < 15000 THEN 'NORMAL'
ELSE 'AlTO'
END as nivel
FROM ventas
-- contabilizar cuantos productos estan en nivel ALTO
SELECT
COUNT(Id) AS itemes,
SUM ( CASE
WHEN nivel = 'ALTO' THEN 1
ELSE 0 END
) AS itemes_altos
FROM ventasOperadores lógicos
-- Ambas condiciones deben cumplirse SELECT * FROM clientes WHERE nacimiento > ‘1995-01-01’ AND puntos > 1000
-- Al menos una condición debe cumplirse SELECT * FROM clientes WHERE nacimiento > ‘1995-01-01’ OR puntos > 1000
-- Negar cierta condición SELECT * FROM clientes WHERE NOT (nacimiento > ‘1995-01-01’)
-- Clientes de alguna de las categorías
SELECT *
FROM clientes
WHERE estado IN ('A', 'B', 'C', 'D')
-- Entre un rango de fechas o números SELECT * FROM clientes WHERE puntos BETWEEN 1000 AND 5000
Uniones
Joins
La herramienta más potente en el modelo relacional. Las sentencias JOIN permiten el uso de datos provenientes de dos o más tablas utilizando como conector entre ellas una columna cómun. Esta columna debe ser del mismo tipo de datos, y generalmente es la clave primaria de ellas (aunque no necesariamente).
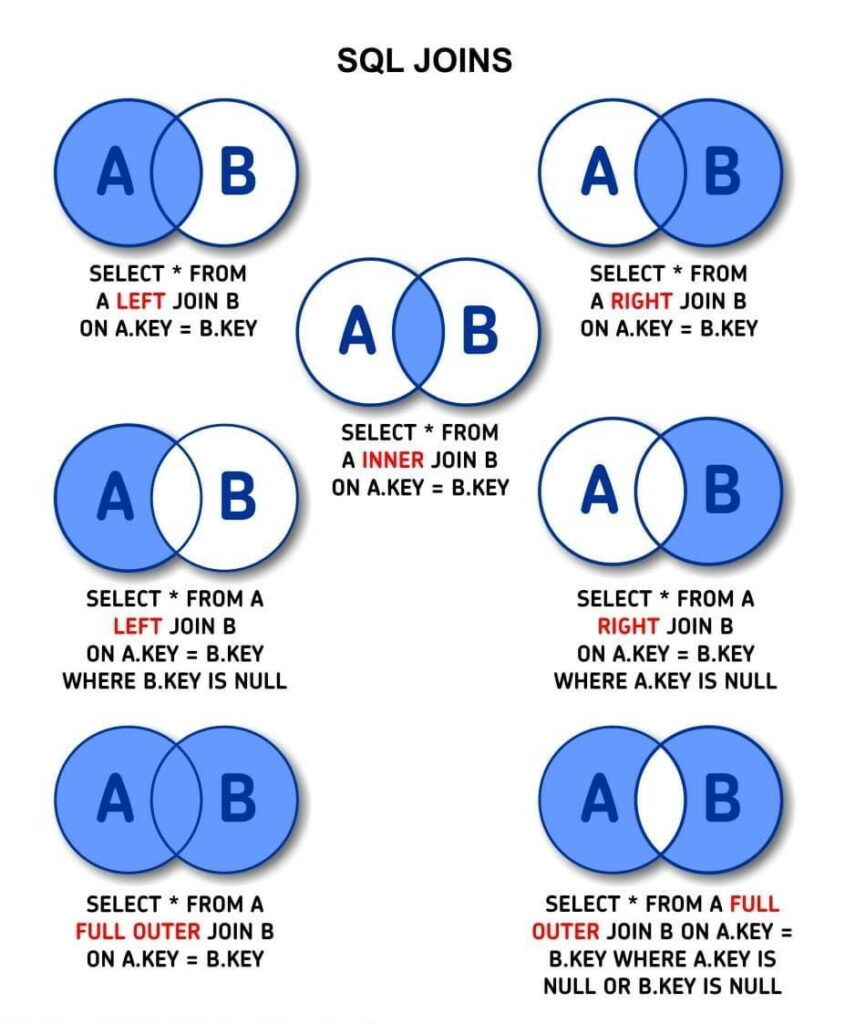
LEFT JOIN
LEFT JOIN o LEFT OUTER JOIN obtiene todos lod datos de la primera tabla (o tablaba izquierda), y solamenta las filas que coinciden desde la segunda tabla (o tabla derecha). en caso de no haber coincidencias desde esta última tabla muestra solo valores nulos.
-- recuperando filas desde una tabla que no poseen correspondencia de filas a otra tabla -- mantiene solo las filas que no corresponden (anti-join) SELECT d.* FROM departamentos d LEFT OUTER JOIN empleados e ON (d.depto = e.depto) WHERE e.deptno is null
-- seleccionar registros de dos tablas y luego correlacionar con una tercera tabla. empleados y departamentos y bono entregado (no todos los empleados reciben bono)
SELECT e.ename, d.loc, eb.bono
FROM empleados e
JOIN departamentos d ON (e.deptno=d.deptno)
LEFT JOIN bonos eb ON (e.empno=eb.empno)
ORDER BY 2
-- alternativa
SELECT e.ename, d.loc,
(SELECT eb.bono FROM bonos eb
WHERE eb.empno=e.empno) as bono
FROM empleados e, departamentos d
WHERE e.deptno=d.deptno
-- clientes sin ordenes de compra SELECT distinct a.cliente_id FROM transacciones a LEFT JOIN clientes b ON a.cliente_id = b.cliente_id WHERE b.cliente_id IS NULL
-- cuantos pacientes hay de cada comuna SELECT count(*) cantidad, co_id codigo, co_comuna as comuna FROM pacientes p LEFT JOIN comunas c on (p.pa_comuna = c.co_id) WHERE pa_comuna !='00000' GROUP BY co_id, pa_comuna ORDER BY cantidad DESC;
-- cuantas consultas por usuario medico (completo) SELECT count(ex_idm),md_nombre||' '||md_apellido , ex_idm as medicos FROM consultas c LEFT JOIN medicos ON (ex_idm=md_id) GROUP BY ex_idm, md_nombre||' '||md_apellido
INNER JOIN
INNER JOIN o JOIN regresa solamente los registros coincidentes en ambas tablas.
-- detalles de orden y producto SELECT a.*,b.* FROM ventas as a INNER JOIN productos as b ON a.idproducto = b.idproducto
-- Encontrar el total de camas (beds) por nacionalidad dentro de los registros de Airbnb -- en las tablas airbnd_apartments con airbnd_hosts mediante la columna relacionada "host_id" SELECT nationality, SUM(n_beds) AS total_beds_available FROM airbnb_hosts h INNER JOIN airbnb_apartments a ON h.host_id = a.host_id GROUP BY nationality ORDER BY total_beds_available DESC;
UNION
-- apilando registros de 2 o mas tablas. Deben tener las mismas cantidad de columnas y tipo de dato. Incluye los duplicados si existen.
SELECT nombre, departamento
FROM empleados
WHERE deptno = 20
UNION ALL
SELECT deptnombre, deptno
FROM departamentos
UNION ALL
SELECT '++++', NULL
FROM tabla1
-- No se incluyen los duplicados
SELECT nombre, departamento
FROM empleados
WHERE deptno = 20
UNION
SELECT deptnombre, deptno
FROM departamentos
UNION
SELECT '++++', '++++'
FROM tabla1
-- seleccionar las filas de dos o mas tablas combinando la información de varias columnas SELECT e.ename, d.loc, FROM empleados e, departamentos d WHERE e.deptno = d.deptno AND deptno = 10 -- alternativa SELECT e.ename, d.loc, FROM empleados e INNER JOIN departamentos d ON (e.deptno = d.deptno) WHERE deptno = 10
-- encontrar filas iguales entre 2 tablas, esto es filas similares en valores
SELECT col1,col2,col3,col4,col5
FROM tabla1
WHERE (col2,col3,col4) in (
SELECT col2,col3,col4 FROM tabla1
INTERSECT
SELECT col2,col3,col4 FROM tabla2
)
-- version alternativa
SELECT e.empno,e.ename,e.job,e.sal,e.deptno
FROM tabla1 e JOIN tabla2
ON (e.ename = v.ename
and e.job = v.job
and e.sal = v.sal )
-- actualizar en base a un join UPDATE usuarios AS u SET rute = r.rut, id=r.idf, passwd=md5(substring(r.rut from 1 for 4)) FROM ruts AS r WHERE u.id = r.ido
Duplicados
Registros duplicados
-- encontrar registros duplicados
SELECT max(pa_id), pa_apellido,pa_nombre, COUNT(pa_id) AS NumOccurrences
FROM bio_pacientes
GROUP BY pa_apellido, pa_nombre
HAVING ( COUNT(pa_id) > 1 )
-- alternativa
SELECT nombre, rut, COUNT(*) AS registros
FROM clientes
GROUP BY nombre, rut
HAVING ( COUNT(*) > 1 )
-- full detalle de cuales registros tienen duplicados
SELECT * FROM
(
SELECT column_a, column_b, column_c, count(*) as records
FROM tabla1
GROUP BY 1,2,3
) a
WHERE records = 2
-- listar los registros duplicados en base a una columna determinada (col_1)
SELECT id, col_1, col_2
FROM ( SELECT *,
COUNT(*) OVER(PARTITION BY col_1) N
FROM codigos) as A
WHERE N > 1
-- Eliminar solo duplicados
DELETE FROM tabla1
WHERE NOT campo IN
(select max(campo)
FROM tabla1 GROUP BY campo)
-- alternativa
DELETE FROM tabla_1 a USING (
SELECT MIN(ctid) as ctid, key
FROM tabla_1
GROUP BY key HAVING COUNT(*) > 1
) b
WHERE a.key = b.key
AND a.ctid <> b.ctid
-- en MySQL mediante una tabla temporal donde se registran los duplicados
CREATE temporary TABLE temp_table (id int);
INSERT temporal_table
(id)
SELECT id
FROM your_table t1
WHERE EXITS
(
SELECT *
FROM your_table t2
WHERE t2.col_1 = t1.col_1
and t2.col_2 = t1.col_2
and t2.col_3 = t1.col_3
and t2.id > t1.id
);
-- ahora se compara ambas tablas para eliminar lso duplicados
DELETE
FROM your_table
WHERE id in (SELECT id FROM temporal_table);
-- Remover duplicados SELECT DISTINCT estado FROM clientes
Subconsultas
Subquery
-- distribución de ordenes por cliente SELECT orders, count(*) as num_customers FROM ( SELECT customer_id, count(order_id) as orders FROM orders GROUP BY 1 ) a GROUP BY 1
-- queremos conocer el producto mas caro SELECT nombre, codigo, precio FROM productos WHERE precio=(SELET max(precio) FROM productos)
Las subconsultas que retornan un solo valor escalar se utiliza con un operador de comparación o en lugar de una expresión
SELECT CAMPOS FROM TABLA WHERE CAMPO OPERADOR (SUBCONSULTA) SELECT CAMPO OPERADOR (SUBCONSULTA) FROM TABLA
-- conocer el valor de un artículo determinado ('pesa') y la diferencia con el artículo mas costoso
SELECT articulo, precio,
precio - (SELECT max(precio) FROM libros) as diferencia
FROM productos
WHERE articulo = 'pesa'
-- Actualizamos el precio del producto con el valor mayor: UPDATE productos SET precio=45 WHERE valor = (SELECT max(valor) FROM productos)
Pivot
Pivot
Una tabla de pivoteo es una manera de resumir datos en forma de filas y columnas. Dado por los atributos de una columna donde la intersección de fila y columna se utiliza un valor de tipo estadístico como suma , cuenta o promedio.
-- cuadro resumen de las ventas de cada producto por fecha SELECT fecha, sum(case WHEN product = 'polera' THEN monto ELSE 0 END) as poleras, sum(case WHEN product = 'camisa' THEN monto ELSE 0 END) as camisas, sum(case WHEN product = 'zapato' THEN monto ELSE 0 END) as zapatos FROM ordenes GROUP BY 1
-- promedio de valor de propiedades por comuna y numero de dormitorios SELECT comuna, avg(valor) FILTER (WHERE dormitorio = 1) AS "1", avg(valor) FILTER (WHERE dormitorio = 2) AS "2", avg(valor) FILTER (WHERE dormitorio = 3) AS "3", avg(valor) FILTER (WHERE dormitorio = 4) AS "4" FROM propiedades GROUP BY comuna;
--
SELECT * FROM
(
SELECT
category_name,
product_id
FROM
production.products p
INNER JOIN production.categories c
ON c.category_id = p.category_id
) t
PIVOT(
COUNT(product_id)
FOR category_name IN (
[Children],
[Comfort],
[Cruisers],
[Cyclocross],
[Electric],
[Mountain],
[Road])
) AS pivot_table;
-- agregando el año del modelo
SELECT * FROM
(
SELECT
category_name,
product_id,
model_year
FROM
production.products p
INNER JOIN production.categories c
ON c.category_id = p.category_id
) t
PIVOT(
COUNT(product_id)
FOR category_name IN (
[Children],
[Comfort],
[Cruisers],
[Cyclocross],
[Electric],
[Mountain],
[Road])
) AS pivot_table;
En PostgreSQL se requiere habilitar la función tablefunc (CREATE extension tablefunc;) para utilizar crosstab.
-- puntaje obtenido de cada alumno en cada examen SELECT * FROM crosstab( 'SELECT nombre, examen, puntaje FROM examenes ORDER BY 1,2') AS notas (nombre varchar(15),examen1 int, examen2 int, examen3 int, examen4 int);
Agregaciones
Las agregacions son funciones que realizan cálculos en un conjunto de filas retornando un valor.
-- Número de tiendas abierta en domingo SELECT sunday, COUNT(*) AS total_business FROM yelp_business_hours bh LEFT JOIN yelp_business b ON bh.business_id = b.business_id WHERE sunday IS NOT NULL AND is_open = 1 GROUP BY sunday ORDER BY total_business DESC;
-- Total de ventas de Alicia y Renato SELECT SUM(ventas) AS total_ventas FROM ventas_general WHERE vendedor = 'Alicia' OR vendedor = 'Renato'
-- El promedio de la compensación según el cargo y el género del empleado. La compensación se calcula agregando el salario y el bono de cada empleado. No todos los empleados reciben el bono. Un empleado puede recibir más de un bono.
SELECT e.employee_title, e.sex,
AVG(e.salary + b.ttl_bonus) AS avg_compensation FROM sf_employee e
INNER JOIN
(SELECT worker_ref_id,
SUM(bonus) AS ttl_bonus
FROM sf_bonus
GROUP BY worker_ref_id) b ON e.id = b.worker_ref_id GROUP BY employee_title, sex;
-- Encontrar la mayor diferencia en el total de puntajes de todas las tareas. Mostrar la diferencia.
SELECT MAX(puntaje)-MIN(puntaje) AS diferencia FROM
(SELECT student,
SUM(tarea1 + tarea2 + tarea3) AS puntaje
FROM clase_puntajes
GROUP BY student) a;
Series
Series de tiempo
Los análisis de series de tiempo es un tipo común de necesidad de análisis de datos, según necesitamos conocer el comportamiento de una característica en el tiempo, ya sean ventas de productos, ingresos, etc.
La característica principal es el tiempo el que debe ser en formato date o timestamp.
Las funciones generales para manejo de iempo son date_part o extract date_part(‘periodo’, variable) extract(‘periodo’ from variable) donde variable en nuestro columna en formato timestamp y periodo puede ser:
- microsecond
- millisecond
- second
- minute
- hour
- day
- week
- month
- quarter
- year
- decade
- century
- millennium
-- cuadro comparativo de ventas de cada articulo segun fecha de venta. Esto alimenta un gráfico de comparación de cada producto
SELECT date_part('year', fecha) as anual, productos, sum(venta) as total
FROM ventas
WHERE productos IN ('camisa','pantalon','zapato', 'juego')
GROUP BY 1,2
-- calculo de la diferencia entre 2 areas de ventas, secciones masculina y femenina
SELECT date_part('year',sales_month) as ventas_year,
sum(CASE WHEN kind_of_business = 'Mujer' THEN ventas end) as venta_mujer,
sum(CASE WHEN kind_of_business = 'Hombre' THEN ventas end) as venta_hombre
FROM ventas
WHERE tipo_seccion IN ('Hombre', 'Mujer')
GROUP BY 1
-- calculo de la diferencia entre 2 areas de ventas, secciones masculina y femenina
SELECT ventas_year,
venta_mujer - venta_hombre as womens_minus_mens,
venta_hombre - venta_mujer as mens_minus_womens
FROM (
SELECT date_part('year',sales_month) as ventas_year,
sum(CASE WHEN kind_of_business = 'Mujer' THEN ventas end) as venta_mujer,
sum(CASE WHEN kind_of_business = 'Hombre' THEN ventas end) as venta_hombre
FROM ventas
WHERE tipo_seccion IN ('Hombre', 'Mujer')
GROUP BY 1
) a