
Detección de anomalías
La detección de anomalías o datos anormales es una actividad que no es nueva, ya que la identificación de elementos raros, eventos que se diferencian de la mayor parte de los datos, es decir anormales, se conectan con algún tipo de problema, entre los cuales se cuentan:
- fraude bancario
- problemas médicos
- defectos estructurales
- equipos defecuosos
- productos de baja calidad
La detección de anomalías es una técnica utilizada para la identificación de patrones inusuales que no se ajustan al comportamento normal esperado.
Existen tres grandes categorías de técnicas de detección de anomalías:
- Detección de anomalías no supervisada: Las técnicas de detección de anomalías no supervisadas detectan anomalías en un conjunto de datos de prueba no etiquetados bajo el supuesto de que la mayoría de las instancias del conjunto de datos son normales, buscando las instancias que parecen ajustarse menos al resto del conjunto de datos.
- Detección supervisada de anomalías: Esta técnica requiere un conjunto de datos etiquetados como «normales» y «anormales» e implica el entrenamiento de un clasificador.
- Detección de anomalías semisupervisada: Esta técnica construye un modelo que representa el comportamiento normal a partir de un conjunto de datos de entrenamiento normal y, a continuación, comprueba la probabilidad de que una instancia de prueba sea generada por el modelo aprendido.
Para que un evento sea considerado anómalo este debe ocurrir con poca frecuencia, porlo que no son predecibles. Y que además cundo ocurre tiene consecuencias dramáticas o no. Una anomalía por tanto es un patrón en los datos que no se comporta conforme a lo esperado.
Por lo que identificar estos datos es importante dentro del ámbito de la empresa. La pregunta determinante es ¿de qué manera se pueden identificar estos datos? en casos muy simples a plena vista mediante el uso de gráficos. Con el aumento en volumen de datos esto ya no es posible, por tanto debemos recurrir a procedimientos estadísticos y matemáticos.
Eventos anómalos
Para lograr la detección de un evento anómalo mucha veces nos encontramos con lo siguiente:
- La definición de la región normal no es muy clara.
- El límite entre lo normal y anormal no es tan claro.
- La noción de lo que es outlier es variable según la aplicación y el negocio en particular.
- La alta o baja disponibilidad de datos etiquetados para entrenamiento y test.
- El comportamiento normal muchas veces evoluciona. Lo que antes era anormal ya no lo es.
La detección de anomalías es inherente al trabajo con datos, y para una eficiente detección se requieren una gran catidad de datos, pero hay situaciones en las que es propio centrase en éstas anomalías:
- Sistema de detección de intrusiones: transacciones bancarias anómalas (demasiados movimientos en una cuenta), actividad inusual en una red de telefonía móvil.
- Fraude de tarjeta de crédito: localizaciones (orígenes de los movimientos) y movimientos inusuales.
- Eventos obtenidos a partir de sensores: comportamientos extraños que pueden estar asociados al mal funcionamiento de un dispositivo. Usado en mantenimiento predictivo de mecanismos mecánicos.
- Diagnóstico médico: en las imágenes de resonancia magnética, tomografías o electrocardiogramas lo anómalo puede estar asociado a detección de tumores o disfunciones biológicas.
- Ciencias de la tierra: anomalías ambientales, uso del suelo, condiciones ambientales anómalas.
- Procesamiento de imágenes: Eliminación de la pixelación que impide una mejor interpretación de una imagen.
- Fiscalización: Identificación de contratos sospechosos de no cumplir la normatividad de contratación estatal.
- Producción: El aseguramiento de la calidad en los procesos productivos requiere de la identificación de productos defectuosos, particularmente en la producción de grandes volúmenes.
Tipos de anomalías
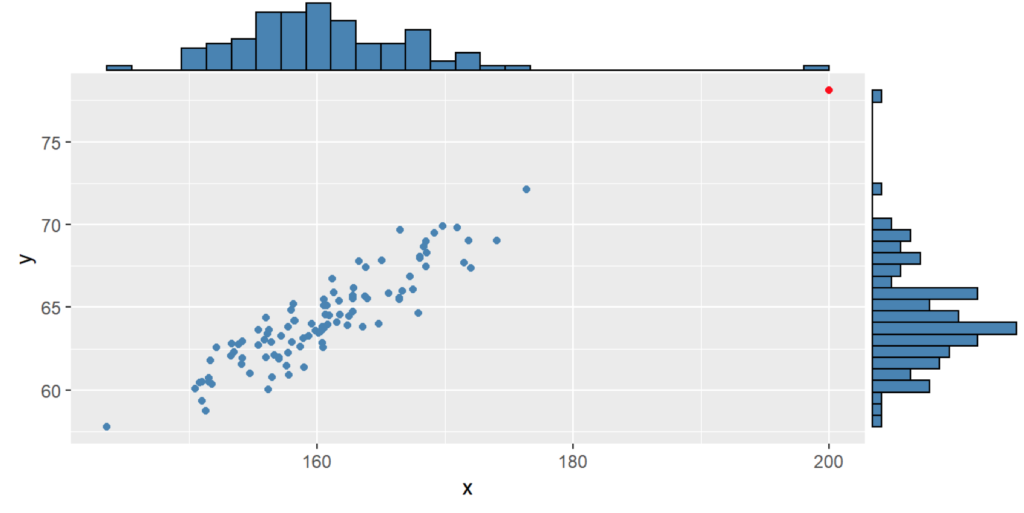
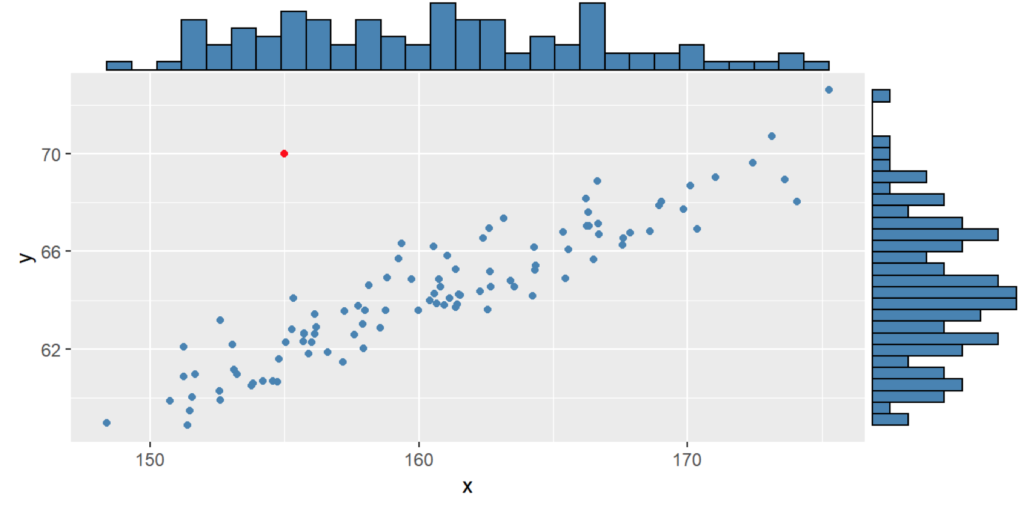
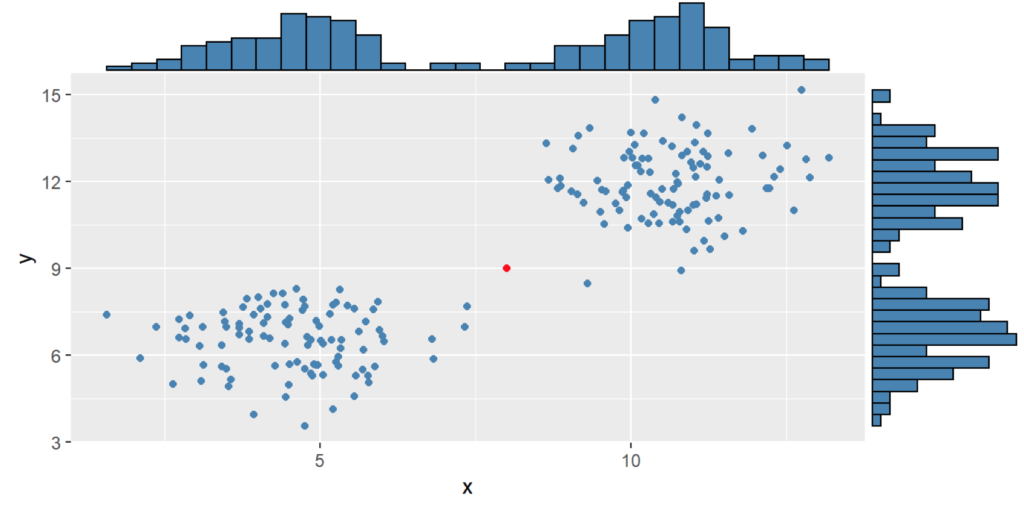
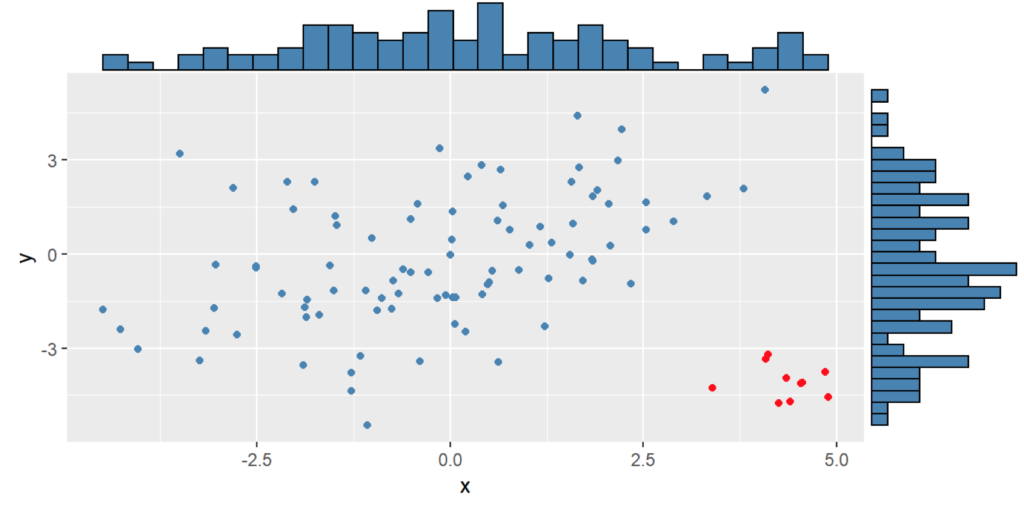
Análisis univariado
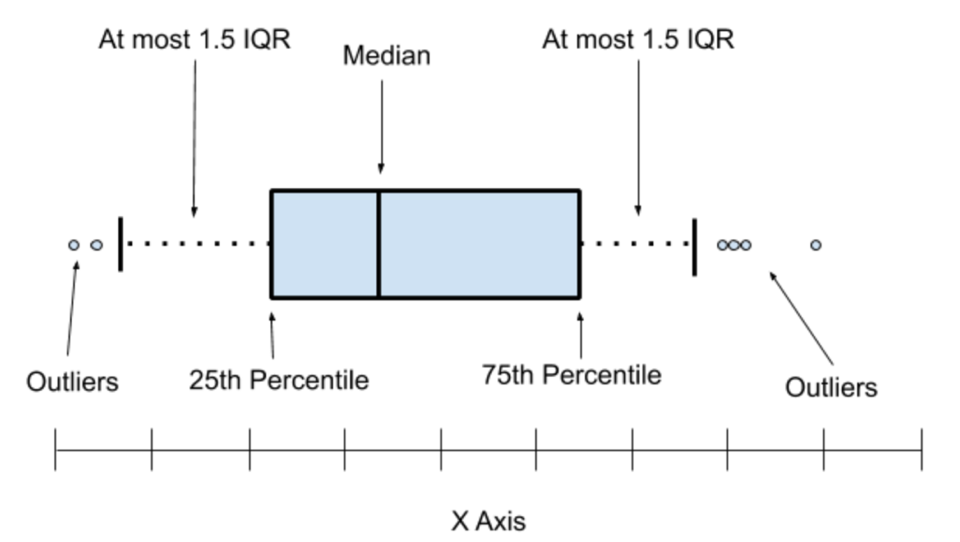
El primer caso que se trabaja es la definición de un dato anómalo cuando se trabaja con una única variable a la vez. El primer contexto en el que se encuentran es en el diagrama de caja o boxplot. El Diagrama de caja se construye con base en los cuartiles (ver Figura ):
- Cuartil 1 (q1): valor a partir del cual el 25% de los datos tienen un valor menor a éste. O leído al revés, el valor a partir del cual el 75% de los datos tienen un valor mayor a éste.
- Ojo. El 25% hace referencia a la cantidad de datos, no a sus valores.
- Cuartil 2 (q2): valor a partir del cual el 50% de los datos tienen un valor menor. Se denomina también mediana. Es un valor robusto frente a datos extremos, es decir, no se afecta por la presencia de datos extremos.
- Cuartil 3 (q3): valor a partir del cual el 75% de los datos tienen un valor menor a éste. O leído al revés, el valor a partir del cual el 25% de los datos tienen un valor mayor a éste.
- Rango intercuartil (RI): La diferencia entre el cuartil 3 y el 1. RI=q3−q1
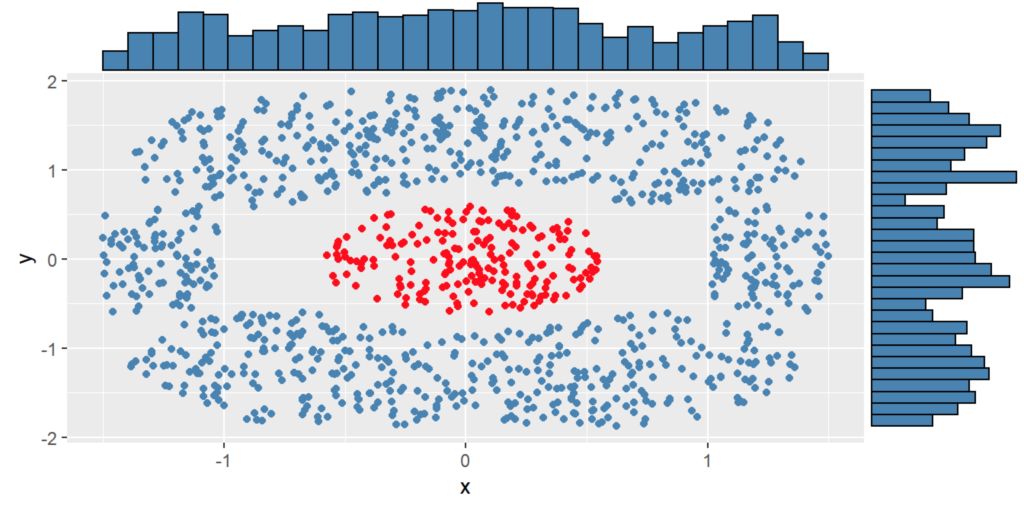
Análisis estadístico multivariado
Cuando se trata de mútiples variables asociadas, se utilizan técnicas para reducir el número de variables y de esta manera hacerlo más manejable, esto se conoce como reducción de dimensionalidad. Una de estas técnicas es el Análisis de Componentes Principales (PCA), que implementa un mapeo lineal de los datos basado en la varianza de los datos.
Isolation Forest
Una técnica popular para la detección de anomalías es el bosque de aislamiento, una técnica de detección de anomalías no supervisada que es similar al bosque aleatorio, que se construye sobre la base de múltiples árboles de decisión; el bosque de aislamiento funciona con el principio de que las anomalías son las observaciones que son diferentes de los puntos de datos que tenemos, sigue el enfoque de procesamiento de las muestras y características seleccionadas al azar para encontrar los valores atípicos en los datos.
Los atributos de los datos se seleccionan aleatoriamente para construir los árboles de decisión, y el camino más corto de los árboles de decisión se considera como valores atípicos que son fáciles de aislar de los datos, este proceso continúa hasta que se procesan todos los puntos de datos. Al final del nivel de aislamiento de cada dato, se anota el punto, y luego se genera la puntuación de anomalía, que define si el punto de datos en particular es un valor atípico o no, si la puntuación de anomalía es cercana a 1, es probable que sea un valor atípico, y si la puntuación de anomalía es inferior a 0,5 entonces ese punto de datos no es una anomalía.
Cuando la puntuación de la observación es cercana a 1, la longitud del camino es muy pequeña, y entonces el punto de datos se aísla fácilmente. Tenemos una anomalía.
Cuando la puntuación de esa observación es inferior a 0,5, la longitud del camino es grande, y entonces tenemos un punto de datos normal.
Si todas las observaciones tienen una puntuación de anomalía de alrededor de 0,5, entonces toda la muestra no tiene una anomalía.
Notebook: https://bit.ly/3CxLZSQ