
Calidad de datos
Este artículo es un extracto del libro Base de Datos el camino de los datos a la información actualmente en construcción.
Estamos en la era del dato, Big Data o de la información si se quiere (casi lo mismo pero no). Sin embargo, no siempre necesito acceso a «Big data» para obtener buena información o procesos de inteligencia artificial o de aprendizaje de cualquier tipo. Importa más la calidad que la cantidad, ya lo mencionó Andrew Ng recientemente.
No existen estandarizaciones en lo que se refiere a calidad de datos (Data Quality). Mantener la exactitud y la integridad de todos los tipos de datos en toda la organización es trabajar por su aptitud para cumplir con su propósito en un contexto dado.
Calidad
Calidad de datos es la cualidad de un conjunto de información recogida en una base de datos, un sistema de información que reúne entre sus atributos los siguientes:
- Exactitud
- Complejidad
- Integridad
- Actualización
- Coherencia
- Relevancia
- Accesibilidad
- Confiabilidad
Asumir que la calidad de los datos es buena puede ser un error fatal para la analítica de negocios. Se recomienda construir un repositorio (datawarehouse, datamart) con los datos tratados y limpiados, desde donde alimentar el análisis.
En consecuencia, debería por tanto establecerse un control o conjunto de controles que localizara los errores en los datos y no permitiera la carga de los mismos.
Las comprobaciones se deberán llevar a cabo, de forma manual o automatizada, teniendo en cuenta distintos niveles de detalle y variando los periodos de tiempo, comprobando que los datos cargados coinciden con los de las fuentes de datos origen.
La calidad de los datos es esencial para la consistencia del reporting, la confianza de los usuarios y para la eficacia de los procesos operativos y transaccionales.
El Aseguramiento de la Calidad de los Datos es el proceso de verificación de la fiabilidad y efectividad de los datos, que debe realizarse periódicamente.
Este proceso recupera los datos en bruto y comprueba su calidad, elimina los duplicados y, cuando es posible, corrige los valores erróneos y completa los valores vacíos, es decir se transforman los datos -siempre que sea posible- para reducir los errores de carga. Se obtienen datos limpios y de alta calidad.
Entre los tipos de datos que mayores efectos adversos pueden provocar en términos de calidad se encuentran los tres siguientes:
Datos oscuros
Son los datos que se recopilan, procesan y almacenan como parte de las actividades comerciales cotidianas, pero que no la organización no utiliza con ningún otro fin. Su existencia revela que el sistema de calidad de datos de la empresa no es el óptimo ni está lo suficientemente avanzado, puesto que permite que a la recopilación y gestión de datos les falte eficiencia y eficacia.
Datos sucios
Si en modo local este tipo de datos supone un grave problema de calidad, en un entorno como la nube aún más, en especial en lo que respecta al Intener de las Cosas (IoT)10. En el ámbito de sistemas automatizados, los datos sucios pueden causar a la organización un daño real, al obligarla a incurrir en un costo económico real causado por las acciones automáticas que dan inicio con datos que no son válidos.
Datos No estructurados
Estos datos son de relativa importancia sobre todo dentro de sistemas relacionales donde todos los datos deben ser estructurados. Reciben menos importancia en sistemas NoSQL que tienen capacidad de recibir datos más heterogéneos.En ocasiones, los datos están disponibles, pero no están preparados para su uso. Deben ser enriquecidos de alguna manera para poder considerarse compatibles con el sistema que los va a consumir. Si no se hace, los problemas de calidad empezarán a aparecer.
Aseguramiento
Descubrimiento de datos: proceso de búsqueda, recopilación, organización y notificación de metadatos.
Perfilado de datos: proceso de analizar los datos en detalle, comparándolos con sus metadatos, calculando estadísticas de datos e informando de las medidas de calidad de los datos que se deben aplicar en cada momento.
Reglas de calidad de datos: se orientarán a optimizar el nivel de calidad de los activos informacionales de la organización y, para ello, se basarán en los requisitos de negocio aplicables, las reglas comerciales y técnicas a las que deben adherirse los datos.
Monitorización de la calidad de los datos: la mejora continua requiere de un esfuerzo de seguimiento, que permita comparar los logros con los umbrales de error definidos, la creación y almacenamiento de excepciones de calidad de datos y la generación de notificaciones asociadas.
Reporting de calidad de datos: está relacionado con los procedimientos y herramientas empleadas para informar, detallar excepciones y actualizar las medidas de calidad de datos en curso.
Limpieza de datos: se ocupa de la corrección en curso de las excepciones y problemas de calidad de datos según son notificadas.
Limpieza
Limpieza de datos siempre esta asociado a los objetivos determinados en el proceso de captura de datos. Como se ha mencionado en forma reiterada esto esta definido por las características del negocio de la organización: ¿para qué se estan capturando datos? ¿qué tipo de datos se requieren? según las respuestas se requiere definir diversos procesos de limpieza o ninguno.
Un buen diseño inicial de captura de datos que esta alineado con los requerimientos establecidos, hará practicamente innecesario un proceso que es bastante costoso en recursos humanos.
La limpieza de los datos incluye 5 actividades principales:
- Depurar
- Corregir
- Estandarizar
- Relacionar
- Consolidar
Depurar
Según las necesidades es requisito depurar los datos obtenidos sobre todo si estos difieren de la forma a ser tratados posteriormente. Esta depuración siempre será necesaria cuando no haya congruencia entre el método de captura y el dato definido a capturar. Este proceso consiste en localizar e identificar los elementos individuales de información en las fuentes de datos y los aísla en las estructuras de destino.
Por ejemplo: el caso más común es la captura de los nombres de personas y direcciones; separar el nombre completo en nombre, primer apellido, segundo apellido, o la dirección en: calle, número, piso, etc.
- nombres, apellidos
- nombres, apellido paterno, apellido materno
- dirección
- calle, numero, departamento, sector, comuna, ciudad, región, país
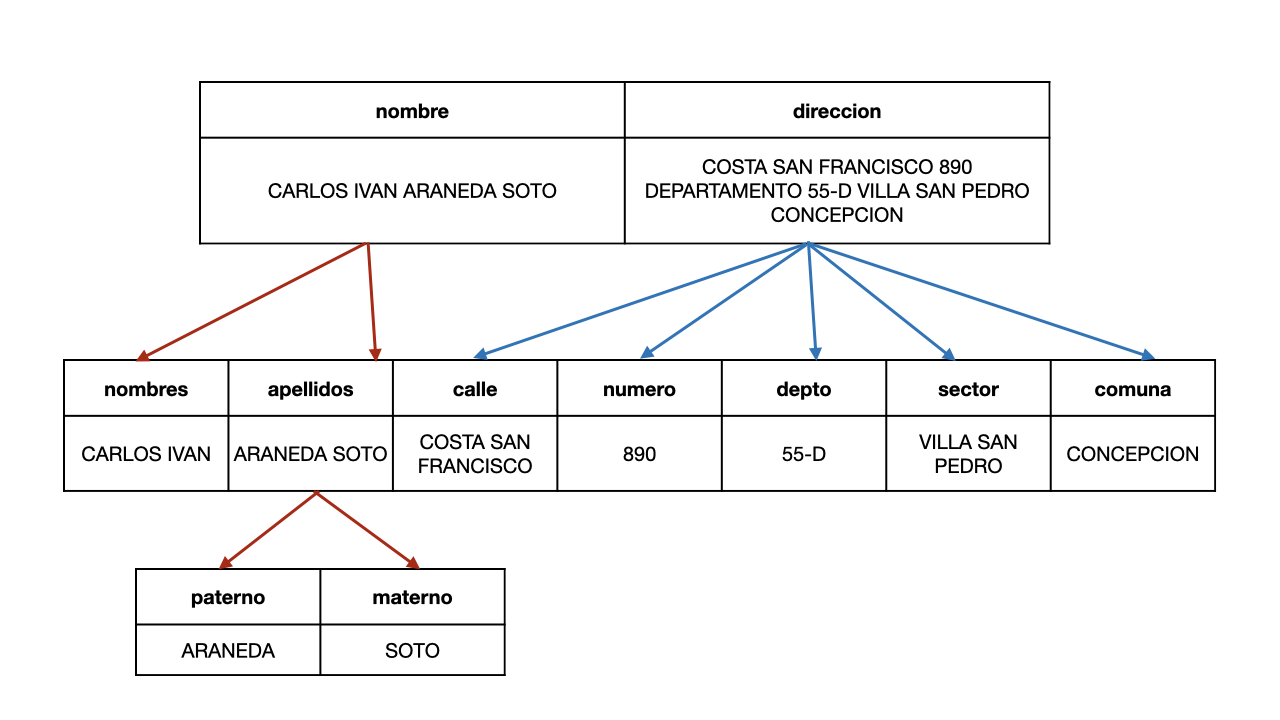
El diseño de la estructura de datos es primordial en los sistemas estructurados de datos (bases de datos relacionales generalmente), dond e la estructura determina la forma de locallizarlos y utilizarlos en la conformación de información.
Corregir
Este proceso corrige los valores individuales de los atributos usando algoritmos de corrección y fuentes de datos externas. Por ejemplo: comprueba una dirección y el código postal correspondiente.
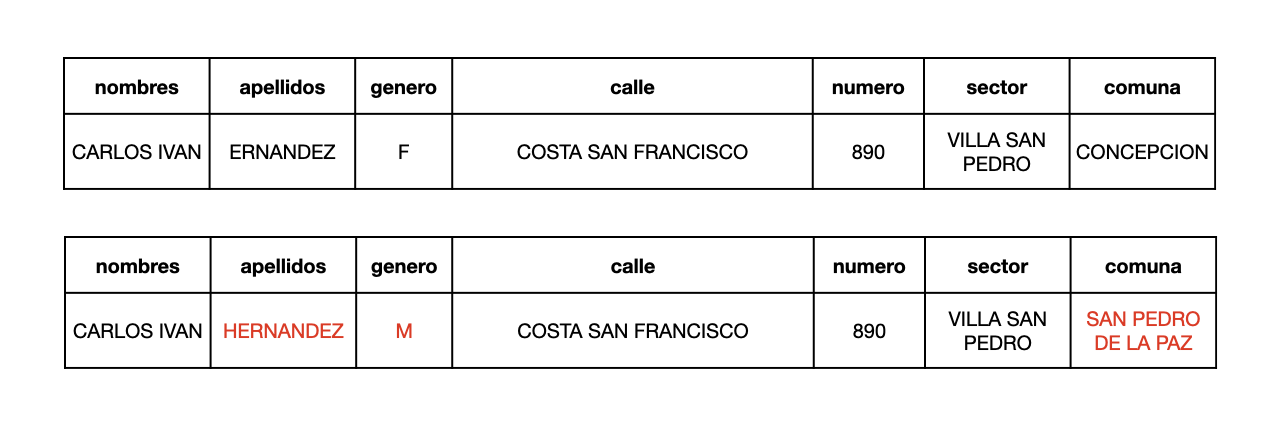
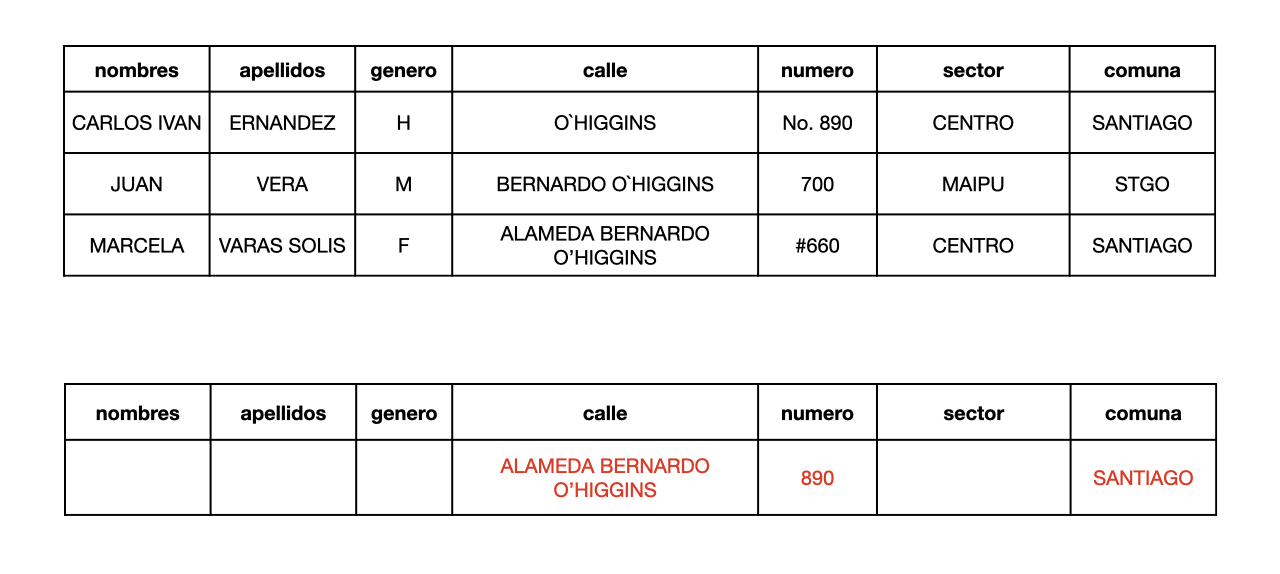
Estandarizar
Este proceso aplica rutinas de conversión para transformar valores en formatos definidos (y consistentes) aplicando procedimientos de estandarización y definidos por las reglas del negocio. Por ejemplo: trato de Sr., Sra., etc. o sustituyendo los diminutivos de nombres por los nombres correspondientes.
Referencias
- Moses Barr, Gavish L. Vorwerck M. Data Quality Fundamentals. 5ed. 2022, Oreilly Media
- King Tim, Schwarzenbach J. Managing Data Quality. 2020, NBN International
- Fryman Lowell. The Data and Analytics Playbook. 2016, Morgan Kaufmann
- Jugulum Rajesh. Competing with High Quality Data. 2014, Wiley
- Sadiq Shazia. Handbook of Data Quality: Research and Practice. 2013, Springer-Verlag
- Samitsch Christoph. Data Quality and its Impacts on Decision-Making. 2015, Gabler verlag