
Evaluación de modelos
Contenidos
¿Es prudente seleccionar siempre aquellos modelos que nos entregan la mejor predicción, la mas exacta? tal vez no deba ser siempre así y cómo medimos la calidad de un modelo y comparamos con el resultado de otros modelos? aquí hago uso de una función de Pycaret que en forma sencilla nos entrega una comparativa para elegir según nuestros objetivos y el contexto de nuestro negocio (siempre importante).
Métricas de clasificación binaria
Las técnicas de clasificación binaria son aquellas cuya meta es predecir categorías discretas donde tenemos uno de dos valores no ordinales. Tales como positivo/negativo, enfermo/sano, verdadero/falso, presencia/ausencia, etc.
Matriz de confusión
La primera herramienta sobre la cual hacemos nuestra evaluaciones es la matriz de confusión, la que presenta tanto los tipos de errores posibles así como los aciertos de un modelo de clasificación. Entrega una serie de métricas que permiten indicar que tan preciso o eficiente es un modelo de predicción en relación a sus resultados correctos o incorrectos. La matriz de confusión entrega 4 valores que corresponden a las 4 combinaciones posibles entre las clases predichas y las reales.
Para clasificaciones binarias (donde tenemos dos alternativas de resultado) la matriz de confusión nos permite visualizar sus aciertos y errores. En un estudio donde se desea determinar la predicción de cáncer (tiene vs no tiene) presenta los casos reales vs los casos predichos (estimados). Genera una diagonal para todos los aciertos, donde acierta los casos positivos (verdaderos positivos, TP) y negativos (verdaderos falsos, TN) y muestra los errores positivos (falsos positivos, FP) y negativos (falsos negativos, FN).
- Verdadero positivo TP: indica que tiene cáncer y si lo tiene (acierto).
- Verdadero negativo TF: indica que no tiene cáncer y realmente no lo tiene (acierto).
- Falso positivo FP: indica que tiene cáncer pero no lo tiene (error tipo I).
- Falso negativo FN: indica que no tiene cáncer, pero si lo tiene (error tipo II).

Pycaret me entrega una evaluación comparativa basada en las métricas antes mencionadas.
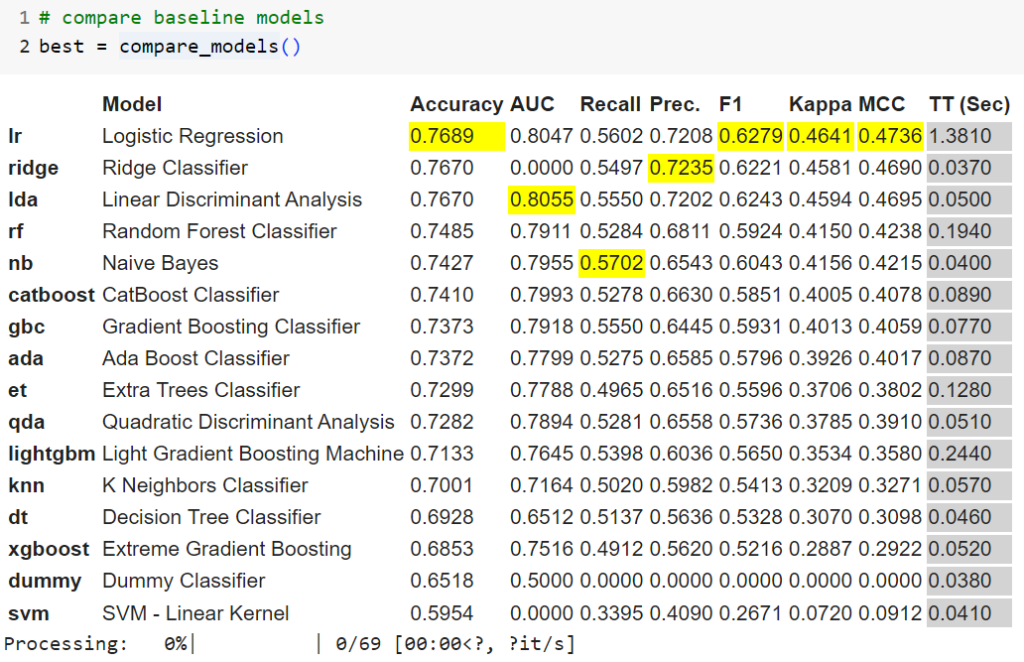
Los resultados destacados en amarillo son recomendaciones de Pycaret en base a sus resultados.
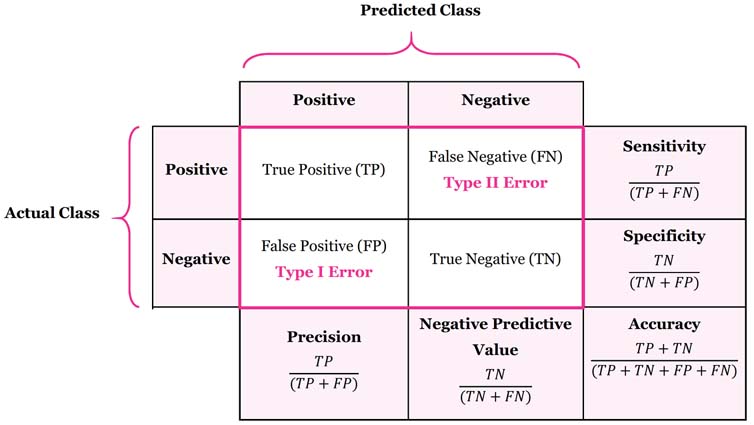
Esta simple matriz ofrece unas métricas útiles para medir que tan bien lo hace un modelo de clasificación en predecir «algo». Estas métricas son:

Exactitud (Accuracy)
Es la proporción de las predicciones correctas (tanto positivas y negativas) sobre el total de predicciones. Se refiere principalmente a la dispersión de los valores obtenidos. A menor dispersión mayor es la exactitud. También se conoce como el ratio de éxito ya que representa las predicciones correctas.


Precisión
La precisión indica que tan cerca está el resultado del valor verdadero. De entre todos los casos positivos cuántos fueron predichos correctamente. Es la proporción de verdaderos positivos de todos los positvos detectados.


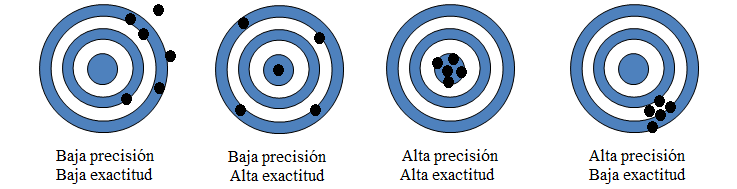
Sensibilidad (Recall)
Es la tasa de casos positivos (tasa positiva real) que fueron correctamente identificados por el modelo. Refleja la capacidad de detectar los casos positivos. también se denomina tasa de verdaderos positivos (True Positive Rate). Un valor bajo indica que no es capaz de detectar todos los casos y se pierden muchos positivos.


Es finalmente el número de verdaderos positivos correctamente clasificados.
Con un 0,90 – 90% es altamente sensible y por ende capaz de detectar los casos relevantes. Si el objetivo es evitar falsos negativos entonces se deberá elegir alta sensibilidad.
Especificidad
Tasa de casos negativos que se han clasificado correctamente. Es la capacidad de detectar los casos negativos. Una alta especificidad es relevante sobre todo en la industria de la salud.


Tiene una alta especifidad, por ende es dificil obtener falsos positivos.
En general se querrá obtener una mayor precisión y sensibilidad ya que detectará la mayoría de los casos bajo interés, sin embargo en el caso de la detección de cáncer tal vez sea más «sano» uno de alta precisión y especificidad, que nos permita detectar de mejor manera los falsos negativos, ya que estos tienen mayor relevancia para los pacientes. No detectar un cancer en un paciente que realmente lo padece puede ocasionar un tratamiento tardío y consecuencias graves para su salud y/o sobrevida.
Si el objetivo es evitar los falsos positivos entonces la elección se basará en una mayor especifidad.
La sensibilidad del modelo equivale a los casos positivos clasificados correctamente. La especifidad del modelo indica la proporción de los casos negativos clasificados correctamente.
F1-score (Valor-F)
Combina las medidas de precisión y sensibilidad, lo que facilita la comparación de estas medidas utilizando la media armónica ya que los valores son proporciones entre 0 y 1. Asume que tanto precision como sensibilidad tienen la misma relevancia.

Kappa
El índice kappa o también llamado kappa de Cohen es un índicador de la concordancia entre valores y que evalua si esta está relacionada a lo que puede generarse por azar. Un valor negativo indica una concordancia débil más de lo esperado. Los valores resultantes estarán entre -1 y +1. Un indicador de valor 1 muestra una concordancia perfecta y 0 es la que se espera en base a las probabilidades (o azar).

En forma general, un valor de kappa > 0,75 indica una concordancia aceptable, aunqe es mejor un kappa > 0,9.
MCC
Matthews Correlation Coefficient o MCC, es una escala métrica para clasificación binaria, que establece un coeficiente de correlación entre la clase verdadera y la predicha. Cuanto mayor sea la correlación entre los valores reales y los predichos, mejor será la predicción.

Cuando el clasificador es óptimo (FP = FN = 0), el valor de MCC es 1 y por tanto se da una correlación positiva perfecta. Cuando entrega valores cercanos a 1 significa que ambas clases se predicen igualmente bien, incluso si alguna de las clases está desproporcionadamente infra o sobre representada.
Cuando es cero significa que es lo mismo que culpar el resultado debido al azar.
Una particularidad de MCC es que es simetrico de tal forma que ninguna clase es más importante que otra.