
Es factible el Low Code Data Mining?
Es factible el «low code data mining», esto es, generar procesos de minería de datos con bajo o nulo uso de códigos de programación? la respuesta corta es sí.
Descubrí hace ya varios años KNIME (Kostanz Information Miner), una herramienta para data mining y data analytics, potente y versátil para estas actividades y que no requiere de conocimientos de programación o especialidad en informática para sacarle el máximo provecho. Es un programa originado en la Universidad de Konstanz en Alemania y que actualmente está radicada comercialmente en Zurich, Suiza.
No requiere ser un especialista en informática, pero para sacarle el provecho al área de minería de datos y analíticas si es necesario conocer los procesos subyacentes, de tal forma de aprovechar al máximo sus capacidades en la forma de componentes y nodos funcionales.
KNIME es gratuito y de código abierto y esta construido en Java sobre plataforma Eclipse. Integra una gran variedad de componentes para aprendizaje automático y minería de datos, así como para el preprocesamiento y modelado de datos. En sus inicios comenzó como una herramienta de investigación para la industria farmacéutica y posteriormente fue abarcando otrás áreas utilizandose actualmente en amplios rubros como CRM, inteligencia empresarial, minería de textos, análisis de datos financieros, ciencias biológicas, y otras.

KNIME tiene las capacidades para automatizar los procesos de captura y análisis de datos de cualquier tipo de organización.
Se integra con Pyhton, R y otros lenguajes de programación para adicionar una mayor cantidad de funciones.
Posee funcionalidades para aprendizaje automático, procesamiento de lenguaje natural y otras técnicas propias de la inteligencia artificial.
Ahora, si no te dedicas a la minería de datos o analíticas, también como herramienta de automatización de procesos (casi un RPA), también te brinda herramientas excelentes. Para ello un caso de uso real y simple:
Caso 1: Proceso mensual
Cada mes (eventualmente) recibía un archivo parte de un proveedor, que consistía en los niveles de uso acumulados de ciertos servicios de comunicación. Estos venían en un archivo de Excel debidamente organizados en columnas constantes, con el detalle de consumo de cada cliente a la fecha de emisión del reporte. Cada recepción requería la realización de una serie de modificaciones/correcciones para la generación de los reportes respectivos de uso:
- Modificación de una columna para la eliminación códigos de país.
- Eliminación de columnas no atingentes.
- Eliminación de registros con consumo nulo.
- Generación de gráficos de consumo mensual y acumulado.
- Crear un nuevo archivo Excel corregido para uso posterior.
Las rutinas indicadas arriba se debían desarrollar con cada entrega. Por tanto la solución KNIME para ello esta resumida en el siguiente flujo.
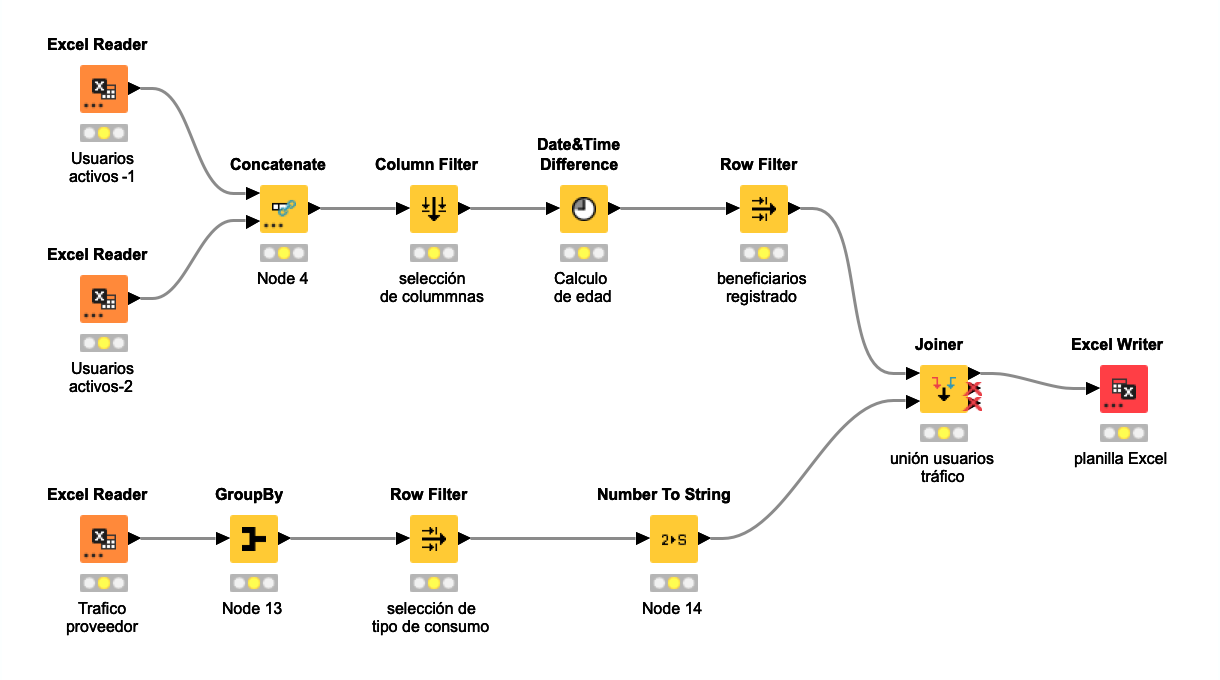
Una vez generado el flujo, cada nueva entrega consistía en ejecutar el proceso y en menos de 30 segundos ya estaba creado el nuevo libro de excel con los datos actualizados. Ya con eso, a mi modo de ver justifica el uso de KNIME como herramienta de procesamiento de datos y automatización.
Caso 2: Creación de un libro Excel y hojas adicionales
Para efectos de este ejemplo el origen de los datos se basará en 3 archivos separados, que en realidad pueden obtenerse desde consultas directas a una base de datos o múltiples bases de datos.

Este flujo resulta en un archivo Excel con 3 hojas separadas por tipo de pago. Genera el libro de excel y mediante control de flujo (verificando que el archivo se haya creado) adiciona una hoja para los pagos en efectivo. Luego se generar una espera de «n» segundos para adicionar la tercera y última hoja de pagos con cheques.
Big data
Las extensiones para el manejo de Big Data incluyen el acceso a Apache Spark y el ecosistema de Apache Hadoop. Además de poseer extensiones para Azure, AWS y Google Cloud Platform.
Las conexiones a las mayores plataformas de datos existentes aseguran que podemos realizar la extracción desde casi cualquier fuente de datos. Esto incluye las bases de datos más populares del mercado.
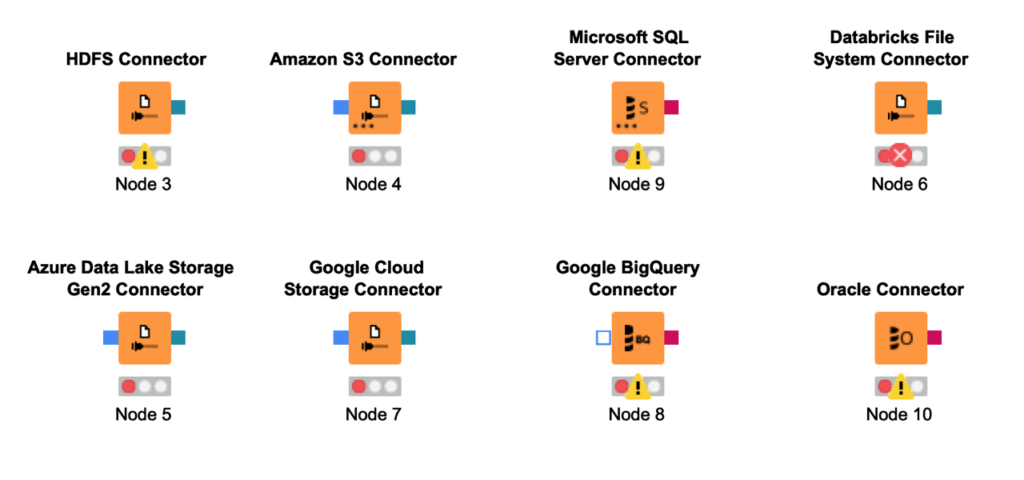
Se incluyen debidamente MySQL, PostgreSQL y otras, además a casi cualquier tipo de archivo, incluyendo páginas web (html).
En términos de Big Data permite el acceso a Apache Spark, Cloudera y otras.
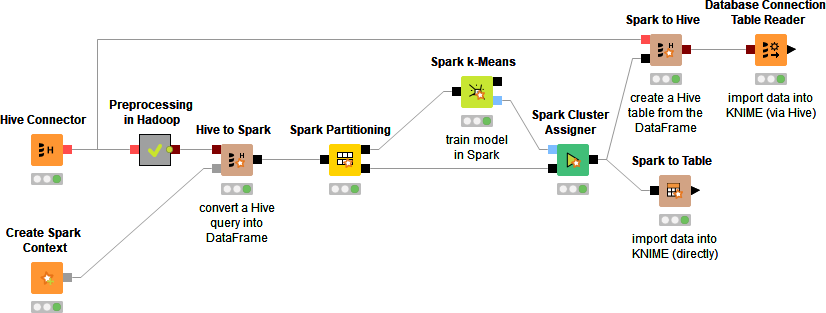
Minería de datos
KNIME posee los componentes necesarios para realizar limpieza de datos, y transformaciones de toda índole que permiten realizar complejos preprocesos de datos.
Aprendizaje automático
Para las tareas de aprendizaje automático KNIME posee las herramientas necesarias para la limpieza de datos, generación de modelos de entrenamiento, partición de los datos, ejecutar diversos algoritmos de ML y visualización de los resultados.

En resumen, KNIME es una herramienta que vale la pena probar y que puede resolver una serie de problemas del ámbito de ETL.
Este artículo es el primero de una serie de artículos que tratarán en mayor profundidad esta herramienta, con ejemplos concretos de uso en el campo del aprendizaje automático y la ciencia de datos.