
Machine Learning
Titanic
Contenidos
Un clásico para el estudio de ML es el conjunto de datos (dataset) de Titanic, pero sabes por qué? pues porque contiene todo lo que un trabajador de datos no desea, mucha variedad y problemas. Solo por enumerar algunos:
- Muchos datos nulos en diversas columnas
- Datos incompletos
- Columnas sin relevancia en el objetivo final (¿seguro?)
- Combinación de datos categóricos y de valor
- Conocemos la historia (el equivalente al conocimiento del negocio)
Finalmente, porque pese a todo podemos seguir haciendo nuevas preguntas sobre estos datos históricos.

Nota curiosa: En realidad existieron 3 barcos identicos al Titanic, los otros fueron el Olympic y el Britannic.
Desafío:
Realiza una búsqueda del dataset Titanic y determina cuántas versiones hay de él, donde varían la cantidad de columnas (variables), cantidad de valores, etc.
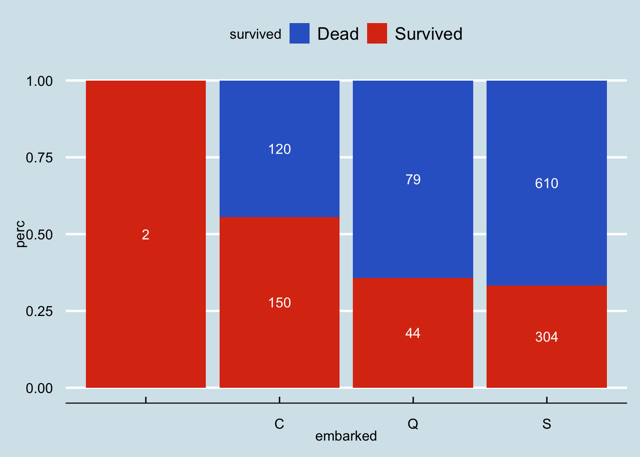
Y en base a estos datasets que circulan por ahí, podemos agregar algunas preguntas a resolver por sobre las típicas, que el sexo, la clase o la edad inciden en la sobrevivencia de los pasajeros.
Pero que hay de las otras variables:
- ¿Tiene alguna relación la cabina donde se alojaba el pasajero?
- ¿Tiene el puerto de embarque alguna relación con la sobrevida?
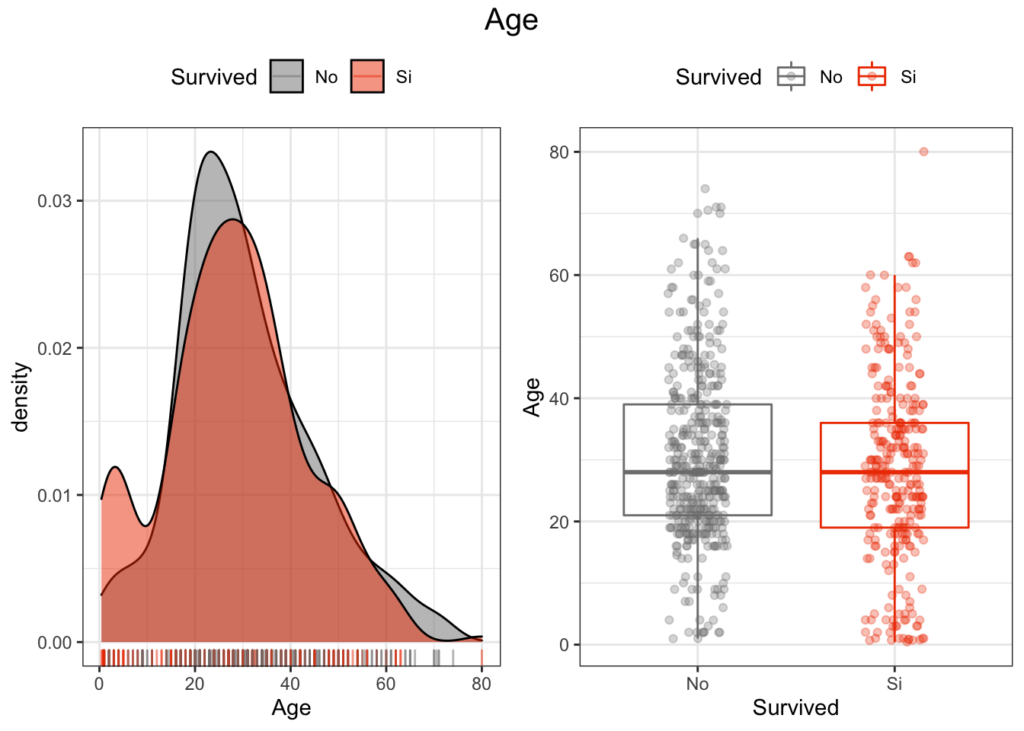
Estimación de sobrevida en base a la cabina del pasajero.
Podría ser explicado por la ubicación de las cabinas respecto de la ubicación de los botes salvavidas. Tarea: Buscar plano del barco.
La supervivencia es buena en la cabina B, D y E. Sin embargo, hay demasiados valores perdidos, entre el 77% de los datos. Lamentablemente, no podemos utilizar esta variable.
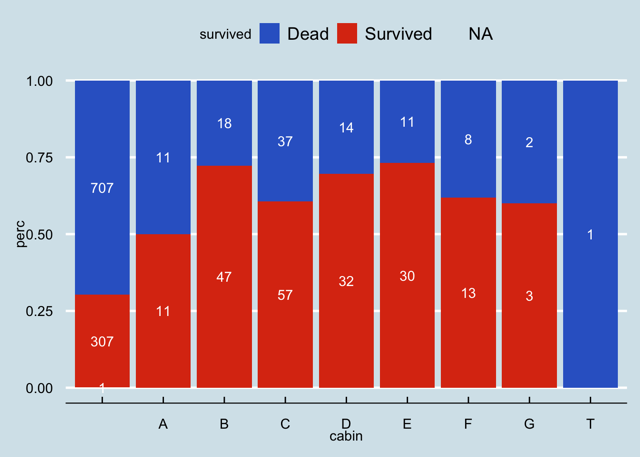
Estimación de sobrevida según el puerto de embarque de los pasajeros.
- S – Southampton, Inglaterra
- C – Cherburgo, Francia
- Q – Queenstown, Irlanda
Parece que los pasajeros que subieron en Cherburgo (C) tienen la mejor tasa de supervivencia. ¿Pero por qué? ¿hay otras variables conjuntas que lo explican?
Titanic hay para rato pues aún hoy se realizan competencias a análisis de datos donde se utilizan estos datasets, particularmente en Kaggle.