
Machine Learning
Aprendizaje supervisado
Contenidos
El aprendizaje supervisado es un método de análisis de datos que deduce información a partir de datos de entrenamiento. Esto es, aprende iterativamente de los datos que le son aportados. Los datos que son entregados estan previamente identificados y etiquetados conocido el valor del atributo objetivo. En base a datos previamente conocidos será capaz de predecir el valor del atributo buscado sobre nuevos datos.
Etiquetas
Una etiqueta es el valor que estamos prediciendo, es decir, la variable y en la regresión lineal simple. La etiqueta podría ser el precio futuro del trigo, el tipo de animal que se muestra en una imagen, el significado de un clip de audio o simplemente cualquier cosa.
Atributos
Un atributo es una variable de entrada, es decir, la variable x en la regresión lineal simple. Un proyecto de aprendizaje automático simple podría usar un solo atributo, mientras que otro más sofisticado podría usar millones de atributos, especificados como: x1, x2, x3,…xn
En el ejemplo del detector de spam en el correo electrónico, los atributos podrían incluir los siguientes:
- palabras en el texto del correo electrónico
- dirección del remitente
- hora del día a la que se envió
- presencia de la frase «un truco increíble» en el correo electrónico
Una vez que el modelo se entrena con ejemplos etiquetados, ese modelo se usa para predecir la etiqueta en ejemplos sin etiqueta. En el detector de spam, los ejemplos sin etiqueta son correos electrónicos nuevos que las personas todavía no han etiquetado.
Un ejemplo es una instancia de datos en particular, x. (La x se coloca en negrita para indicar que es un vector). Los ejemplos se dividen en dos categorías:
- ejemplos etiquetados
- ejemplos sin etiqueta
Un ejemplo etiquetado incluye tanto atributos como la etiqueta. Esto significa lo siguiente:
labeled examples: {features, label}: (x, y)
Los ejemplos etiquetados se usan para entrenar el modelo. En nuestro ejemplo del detector de spam, los ejemplos etiquetados serían los correos electrónicos individuales que los usuarios marcaron explícitamente como «es spam» o «no es spam».
Modelos
Un modelo define la relación entre los atributos y la etiqueta. Por ejemplo, un modelo de detección de spam podría asociar de manera muy definida determinados atributos con «es spam». Destaquemos dos fases en el ciclo de un modelo:
- Entrenamiento significa crear o aprender el modelo. Es decir, le muestras ejemplos etiquetados al modelo y permites que este aprenda gradualmente las relaciones entre los atributos y la etiqueta.
- Inferencia significa aplicar el modelo entrenado a ejemplos sin etiqueta. Es decir, usas el modelo entrenado para realizar predicciones útiles (y’).
En esta categoría se utilizan algoritmos de regresión para la predicción de atributos de tipo numérico y algoritmos de clasificación para atributos de tipo categóricos.
Regresión frente a clasificación
Un modelo de regresión predice valores continuos. Por ejemplo, los modelos de regresión hacen predicciones que responden a preguntas como las siguientes:
- ¿Cuál es el valor de una casa en Santiago?
- ¿Cuál es la probabilidad de que un usuario haga clic en este anuncio?
Un modelo de clasificación predice valores discretos. Por ejemplo, los modelos de clasificación hacen predicciones que responden a preguntas como las siguientes:
- ¿Un mensaje de correo electrónico determinado es spam o no es spam?
- ¿Esta imagen es de un perro, un gato o un perro?

Entrenamiento y pérdida
Pérdida alta en el modelo de la izquierda; pérdida baja en el modelo de la derecha.
Las flechas rojas en la figura izquierda son mucho más largas que las de la figura derecha. Claramente, la línea azul en la figura de la derecha es un modelo de predicción mucho más acertado que la línea azul en la figura de la izquierda.
- La flecha roja representa la pérdida.
- La línea azul representa las predicciones.
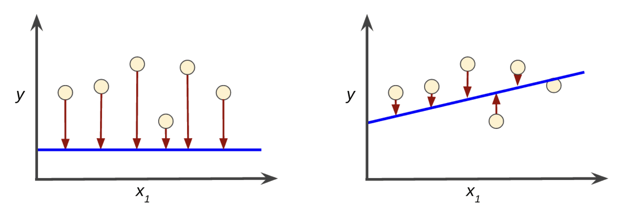
Entrenar un modelo simplemente significa aprender (determinar) valores correctos para todas las ponderaciones y las ordenadas al origen de los ejemplos etiquetados. En un aprendizaje supervisado, el algoritmo de un aprendizaje automático construye un modelo al examinar varios ejemplos e intentar encontrar un modelo que minimice la pérdida. Este proceso se denomina minimización del riesgo empírico.
La pérdida es una penalidad por una predicción incorrecta. Esto quiere decir que la pérdida es un número que indica qué tan incorrecta fue la predicción del modelo en un solo ejemplo. Si la predicción del modelo es perfecta, la pérdida es cero; de lo contrario, la pérdida es mayor. El objetivo de entrenar un modelo es encontrar un conjunto de ponderaciones y ordenadas al origen que, en promedio, tengan pérdidas bajas en todos los ejemplos.
Visión por computadora
El análisis de imágenes vía computadores tiene una larga data sobre todo en el área industrial, como la detección de indicadores en cadenas de procesamiento de manufactura, para el control de calidad y la interacción de las máquinas con el entorno, y con los operadores humanos en el área de robótica colaborativa.
Con la creación de nuevos algoritmos se ha evolucionado a variadas aplicaciones cada vez mas espectaculares desde el punto de vista cotidiano.
- reconocimiento automático de las matrículas de los vehículos
- detección de objetos
- conducción automática
- reconocimiento facial
- interacción humano-máquina

Algoritmos y aplicaciones en aprendizaje supervisado.
| Algoritmo | Aplicación |
| Regresión lineal, logística | Predicción de ventas/precios, elecciones |
| Clasificación | Detección de correo spam, migración de clientes, detección de fraude, Análisis del sentimiento del cliente |
| Árboles de decisión, K-Nearest Neighbor, Bosques aleatorios (Random forest) | Clasificación de rostros, clasificación de documentos, diagnóstico médico, Reconocimiento de imágenes y objetos |
…